

































| Gene Symbol | CC2D2A |
| Entrez Gene ID | 57545 |
| Full Name | coiled-coil and C2 domain containing 2A |
| Synonyms | JBTS9,MKS6 |
| General protein information |
|
| Gene Type | protein-coding |
| Organism | Homo sapiens(human) |
| Genome | |
| Summary | This gene encodes a coiled-coil and calcium binding domain protein that appears to play a critical role in cilia formation. Mutations in this gene cause Meckel syndrome type 6, as well as Joubert syndrome type 9. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Sep 2009]. |
| Disorder MIM: | |
| Disorder Html: | Joubert syndrome 9, 612285 (3); Meckel syndrome 6, 612284 (3); COACH syndrome, 216360 (3) |


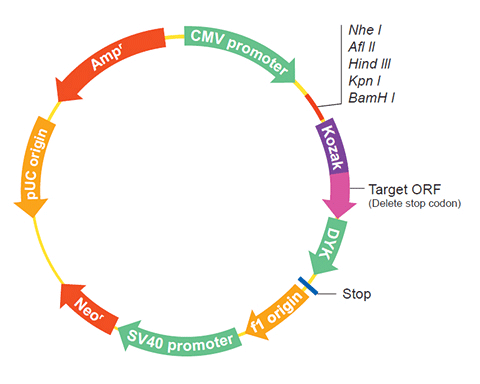
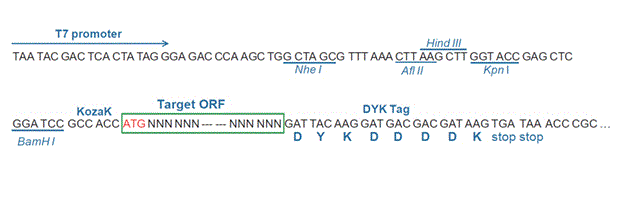
 User Manual
User Manual