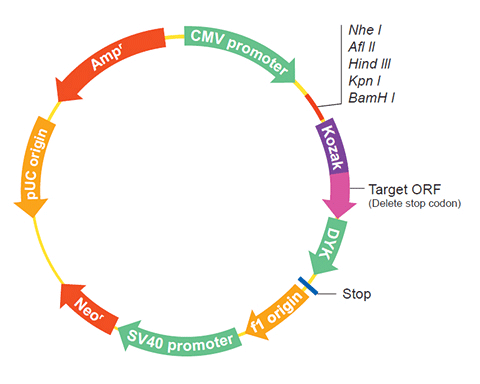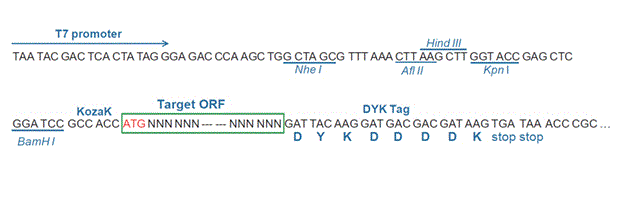


































| Gene Symbol | TLL1 |
| Entrez Gene ID | 7092 |
| Full Name | tolloid like 1 |
| Synonyms | ASD6,TLL |
| General protein information |
|
| Gene Type | protein-coding |
| Organism | Homo sapiens(human) |
| Genome | |
| Summary | This gene encodes an astacin-like, zinc-dependent, metalloprotease that belongs to the peptidase M12A family. This protease processes procollagen C-propeptides, such as chordin, pro-biglycan and pro-lysyl oxidase. Studies in mice suggest that this gene plays multiple roles in the development of mammalian heart, and is essential for the formation of the interventricular septum. Allelic variants of this gene are associated with atrial septal defect type 6. Alternatively spliced transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Mar 2011]. |
| Disorder MIM: | |
| Disorder Html: | Atrial septal defect 6, 613087 (3) |


 User Manual
User Manual