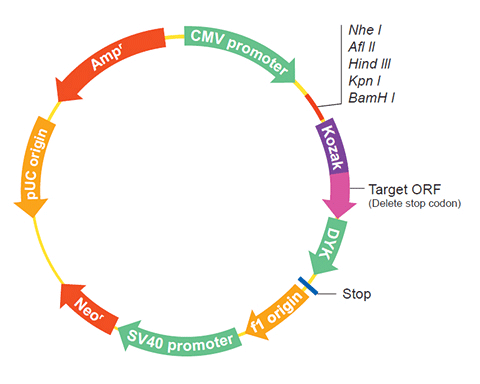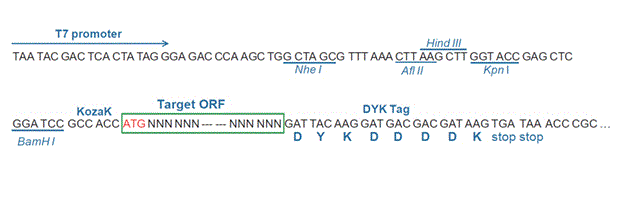


































| Gene Symbol | bmp1.S |
| Entrez Gene ID | 397872 |
| Full Name | bone morphogenetic protein 1 L homeolog |
| Synonyms | bmp-1,bmp1,bmp1-a,bmp1-b,bmp1.S,bmp1b,tld,tolloid,xbmp1,xtld |
| General protein information |
|
| Gene Type | protein-coding |
| Organism | Xenopus laevis(African clawed frog) |

 User Manual
User Manual