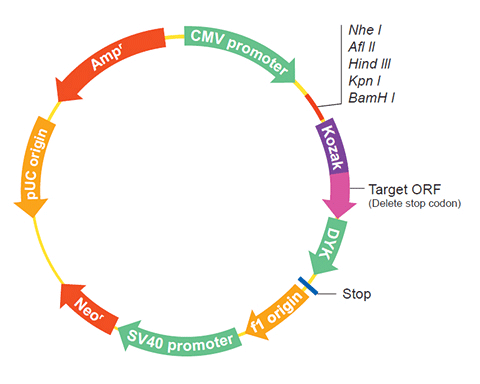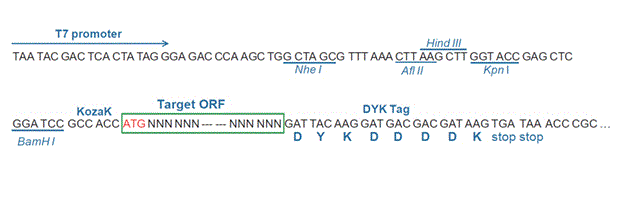


































| Gene Symbol | Ece2 |
| Entrez Gene ID | 107522 |
| Full Name | endothelin converting enzyme 2 |
| Synonyms | 1810009K13Rik,6330509A19Rik,9630025D12Rik,BB127715,Ece-2 |
| General protein information |
|
| Gene Type | protein-coding |
| Organism | Mus musculus(house mouse) |
| Genome |

 User Manual
User Manual